


A new bootable USB solution. Contribute to ventoy/Ventoy development by creating an account on GitHub.
URL Network Version Location Behind Cloudflare? Comment
https://redlib.catsarch.com WWW v0.36.0 🇺🇸 US
https://redlib.privacyredirect.com WWW v0.36.0 🇫🇮 FI
https://redlib.4o1x5.dev WWW v0.36.0 🇭🇺 HU
https://redlib.frontendfriendly.xyz WWW v0.36.0 🇽🇽 XX
https://redlib.reallyaweso.me WWW v0.36.0 🇩🇪 DE A reallyaweso.me redlib instance!
https://reddit.rtrace.io WWW v0.36.0 🇦🇹 AT Caution: +10% increased chance to contract Ligma
https://lr.ptr.moe WWW v0.36.0 🇩🇪 DE ✅
https://redlib.orangenet.cc WWW v0.36.0 🇸🇮 SI orangelib
http://red.lpoaj7z2zkajuhgnlltpeqh3zyq7wk2iyeggqaduhgxhyajtdt2j7wad.onion Tor v0.35.1 🇩🇪 DE Onion of red.artemislena.eu
source : https://github.com/redlib-org/redlib-instances/blob/main/instances.md
URL Network Version Location Behind Cloudflare? Comment
https://safereddit.com WWW v0.31.0 🇺🇸 US SFW only
https://l.opnxng.com WWW v0.31.0 🇸🇬 SG
https://libreddit.projectsegfau.lt WWW v0.31.0 🇱🇺 LU
https://libreddit.bus-hit.me WWW v0.31.0 🇨🇦 CA
https://reddit.invak.id WWW v0.31.0 🇧🇬 BG
https://redlib.catsarch.com WWW v0.31.2 🇺🇸 US
https://reddit.idevicehacked.com WWW v0.31.0 🇺🇸 US
https://redlib.freedit.eu WWW v0.31.2 🇺🇸 US
https://redlib.perennialte.ch WWW v0.31.0 🇦🇺 AU ✅
https://redlib.tux.pizza WWW v0.31.0 🇺🇸 US
https://redlib.vimmer.dev WWW v0.31.2 🇵🇱 PL
https://libreddit.privacydev.net WWW v0.31.0 🇫🇷 FR
https://lr.n8pjl.ca WWW v0.31.2 🇨🇦 CA
https://reddit.owo.si WWW v0.31.0 🇩🇪 DE
https://redlib.ducks.party WWW v0.31.0 🇳🇱 NL
https://red.ngn.tf WWW v0.31.0 🇹🇷 TR
https://red.artemislena.eu WWW v0.31.0 🇩🇪 DE Be crime do gay
https://redlib.dnfetheus.xyz WWW v0.31.0 🇧🇷 BR ✅
https://redlib.cow.rip WWW v0.31.0 🇮🇳 IN ✅
https://libreddit.eu.org WWW v0.31.0 🇩🇪 DE
https://r.darrennathanael.com WWW v0.31.0 🇺🇸 US contact noc at darrennathanael.com
https://redlib.kittywi.re WWW v0.31.0 🇫🇷 FR
https://redlib.privacyredirect.com WWW v0.31.0 🇫🇮 FI
http://redlib.r4focoma7gu2zdwwcjjad47ysxt634lg73sxmdbkdozanwqslho5ohyd.onion Tor v0.31.0 🇩🇪 DE ✅
http://redlib.catsarchywsyuss6jdxlypsw5dc7owd5u5tr6bujxb7o6xw2hipqehyd.onion Tor v0.31.2 🇺🇸 US
http://libreddit.g4c3eya4clenolymqbpgwz3q3tawoxw56yhzk4vugqrl6dtu3ejvhjid.onion Tor v0.31.0 🇫🇷 FR
http://reddit.pk47sgwhncn5cgidm7bofngmh7lc7ukjdpk5bjwfemmyp27ovl25ikyd.onion/ Tor v0.31.0 🇩🇪 DE
http://red.lpoaj7z2zkajuhgnlltpeqh3zyq7wk2iyeggqaduhgxhyajtdt2j7wad.onion Tor v0.31.0 🇩🇪 DE Onion of red.artemislena.eu
source : https://www.mujico.org/post/83177

Avec cet article sur PERL, j'étoffe un peu plus la rubrique Supervision Réseau de Quick-tutoriel, qu
SelfHost/ServicesFOSS
https://github.com/mendel5/alternative-front-ends?tab=readme-ov-file#youtube
Services en ligne :
https://youtubemp3free.com/en/
Outils #
CMD :
https://github.com/yt-dlp/yt-dlp
GUI :

Today we released our archive of data.gov on Source Cooperative. The 16TB collection includes over 311,000 datasets harvested during 2024 and 2025, a complete archive of federal public datasets linked by data.gov. It will be updated daily as new datasets are added to data.gov.
This is the first release in our new data vault project to preserve and authenticate vital public datasets for academic research, policymaking, and public use.
We’ve built this project on our long-standing commitment to preserving government records and making public information available to everyone. Libraries play an essential role in safeguarding the integrity of digital information. By preserving detailed metadata and establishing digital signatures for authenticity and provenance, we make it easier for researchers and the public to cite and access the information they need over time.
In addition to the data collection, we are releasing open source software and documentation for replicating our work and creating similar repositories. With these tools, we aim not only to preserve knowledge ourselves but also to empower others to save and access the data that matters to them.
For suggestions and collaboration on future releases, please contact us at publicdata@law.harvard.edu.
This project builds on our work with the Perma.cc web archiving tool used by courts, law journals, and law firms; the Caselaw Access Project, sharing all precedential cases of the United States; and our research on Century Scale Storage. This work is made possible with support from the Filecoin Foundation for the Decentralized Web and the Rockefeller Brothers Fund.

Awesome Privacy - A curated list of services and alternatives that respect your privacy because PRIVACY MATTERS. - pluja/awesome-privacy

Take back control of your email with this easy-to-deploy mail server in a box.
Decompilation of 3D Pinball for Windows – Space Cadet - k4zmu2a/SpaceCadetPinball
Linux running inside a PDF file via a RISC-V emulator - ading2210/linuxpdf

Generate audiobooks from e-books. Contribute to santinic/audiblez development by creating an account on GitHub.
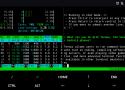
Running LLaMA, a ChapGPT-like large language model released by Meta on Android phone locally.

I use antimatter15/alpaca.cpp, which is forked from ggerganov/llama.cpp.
Alpaca is the fine-tuned version of LLaMA which was released by Stanford University. The alpaca.cpp could run on CPU only mode.
1. Environment
- Device:Xiaomi Pocophone F1
- Android 13
- SoC:Qualcomm Snapdragon 845
- RAM: 6GB
2. Compile alpaca.cpp
Please install Termux first. Then choose one methods from below to compile Alpaca.cpp on your device.
Alpaca requires at leasts 4GB of RAM to run. If your device has RAM >= 8GB, you could run Alpaca directly in Termux or proot-distro (proot is slower). Devices with RAM < 8GB are not enough to run Alpaca 7B because there are always processes running in the background on Android OS. Termux may crash immediately on these devices.
Or you could root your phone and setup a chroot environment. Then mount a swapfile to get more RAM on your device.
2.1. Compile Alpaca.app in Termux
- Install these packages
pkg install clang wget git cmake- Download Android NDK
wget https://github.com/lzhiyong/termux-ndk/releases/download/ndk-r23/android-ndk-r23c-aarch64.zip
unzip android-ndk-r23c-aarch64.zip
export NDK=~/android-ndk-r23c-aarch64https://github.com/lzhiyong/termux-ndk/releases
- Complile Alpaca.cpp and download the model
git clone https://github.com/rupeshs/alpaca.cpp.git
cd alpaca.cpp
mkdir build-android
cd build-android
cmake -DCMAKE_TOOLCHAIN_FILE=$NDK/build/cmake/android.toolchain.cmake -DANDROID_ABI=arm64-v8a -DANDROID_PLATFORM=android-23 -DCMAKE_C_FLAGS=-march=armv8.4a+dotprod ..
make -j8
wget https://huggingface.co/Sosaka/Alpaca-native-4bit-ggml/resolve/main/ggml-alpaca-7b-q4.bin- Run it
./chat2.2. In Chroot
-
Install Chroot Ubuntu and log in to Ubuntu.
-
If your devices has RAM lower than 8GB, it is recommened to mount a SWAP file.
dd if=/dev/zero of=/swapfile bs=1M count=8192 status=progress
chmod 0600 /swapfile
mkswap /swapfile
swapon /swapfile- Install dependencies, compile the program, and download the model.
apt install build-essential wget
git clone https://github.com/antimatter15/alpaca.cpp
cd alpaca.cpp
make chat
wget https://huggingface.co/Sosaka/Alpaca-native-4bit-ggml/resolve/main/ggml-alpaca-7b-q4.bin- Run it.
./chat2.3. In Proot
- Install Proot Debian and log in to Debian.
proot-distro login debian --shared-tmp- Install dependencies, compile the program, and download the model.
apt install build-essential wget
git clone https://github.com/antimatter15/alpaca.cpp
cd alpaca.cpp
make chat
wget https://huggingface.co/Sosaka/Alpaca-native-4bit-ggml/resolve/main/ggml-alpaca-7b-q4.bin- Run it.
./chat3. Usage
-
Now you can start chattig with Alpaca.

-
It will takes Alpaca 30 seconds to start answering your questions.

-
What can you do with Termux? Well, this looks like the answers from Termux official website :)
](https://links.melissandre.dev//en-us/posts/minecraft-java-edition-termux-proot/)
Convert ✓ HTML to Markdown effortlessly with our ✓ online tool, ensuring ✓ CommonMark compliance and ✓ local data processing for privacy.

PipeWire Guide. Learn about how PipeWire gives your Linux system a Professional Audio/Video Processing workflow. - mikeroyal/PipeWire-Guide
ShellCheck finds bugs in your shell scripts
Manage multiple runtime versions with a single CLI tool

A shell script for searching for links on torrent sites - TUVIMEN/torge